Kakao has made history as the first South Korean company to open-source both a high-performing MLLM and a mixture of experts (MoE) AI model. On July 24, the company announced the global release of two advanced models — Kanana-1.5-v-3b, which can interpret both text and image inputs, and Kanana-1.5-15.7b-a3b, a resource-efficient MoE model. Both models are now available to developers and researchers via the AI collaboration platform Hugging Face.
This move marks another step in Kakao’s efforts to expand open access to cutting-edge AI tools while showcasing its in-house development capabilities. As a participant in the Korean government’s “Independent AI Foundation Model Project,” Kakao aims to support broader AI adoption and strengthen the domestic AI ecosystem. The company also emphasized that these models represent the best performance among those released locally.
The latest release comes just two months after Kakao open-sourced its first set of four Kanana-1.5 models. The company described the new models as a major step forward in performance and cost-effectiveness, targeting real-world applications and reducing reliance on foreign AI technologies.
“It’s not just a technical upgrade — it represents a move toward deploying AI in actual services while advancing Korea’s AI independence,” said Kim Byung-hak, head of Kanana Alpha at Kakao.
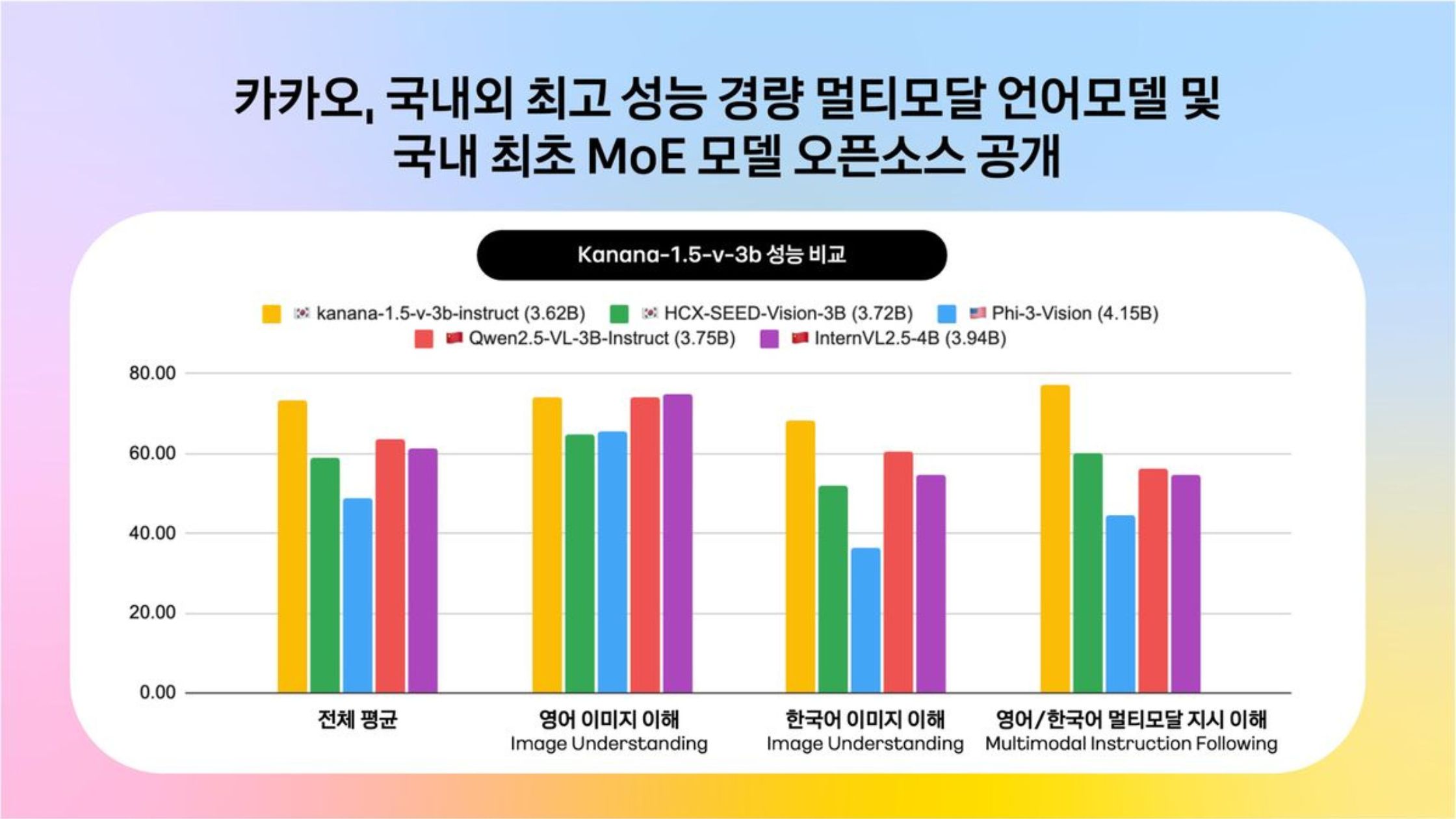
Developed entirely using Kakao’s in-house technology, the Kanana-1.5-v-3b is a lightweight multimodal language model with 3 billion parameters. It is designed to understand and respond to both text and image inputs in Korean and English.
The model demonstrated top-tier performance among Korean models of similar size, outperforming domestic counterparts in instruction-following benchmarks by 128%. Kakao achieved this using training techniques such as human preference alignment and knowledge distillation from larger models.
Kanana-1.5-v-3b is flexible in application, making it suitable for tasks such as image and text recognition, storytelling, identifying cultural landmarks, analyzing data charts, and solving math problems. For example, the model can recognize locations like Cheonggyecheon in Seoul from uploaded images, showcasing its strong visual understanding.
Despite its compact size, the model’s performance in processing image-based Korean and English documents rivals global models like GPT-4o. It also recorded high scores in various international benchmarks, indicating its competitiveness on a global scale. Kakao emphasized that the model strikes a strong balance between performance and resource efficiency, making it attractive for researchers and developers.
The second model, Kanana-1.5-15.7b-a3b, is built using a Mixture of Experts (MoE) architecture. It activates only a subset — about 3 billion — of its 15.7 billion total parameters during inference. This selective activation greatly reduces computing costs while maintaining high performance. The model was upcycled from Kakao’s earlier 3B parameter model, enabling efficient scaling without requiring a complete restart.
MoE models are increasingly used in the AI industry due to their ability to deliver strong results at lower operational costs. Kakao’s MoE model is seen as a practical option for businesses and developers looking to adopt high-performance AI without the financial burden of running dense models. The company expects this architecture to be especially useful in commercial environments where cost control is essential.
Kakao plans to continue expanding its Kanana series and will unveil new reasoning models in the second half of the year. By applying the commercially friendly Apache 2.0 license to its models, the company encourages open innovation and supports startups, academics, and developers. Through these efforts, Kakao aims to strengthen Korea’s AI capabilities and push toward the development of globally competitive large-scale models.
Image credits: Kakao